
Association Rule in Data Mining – Rules, Uses and Works
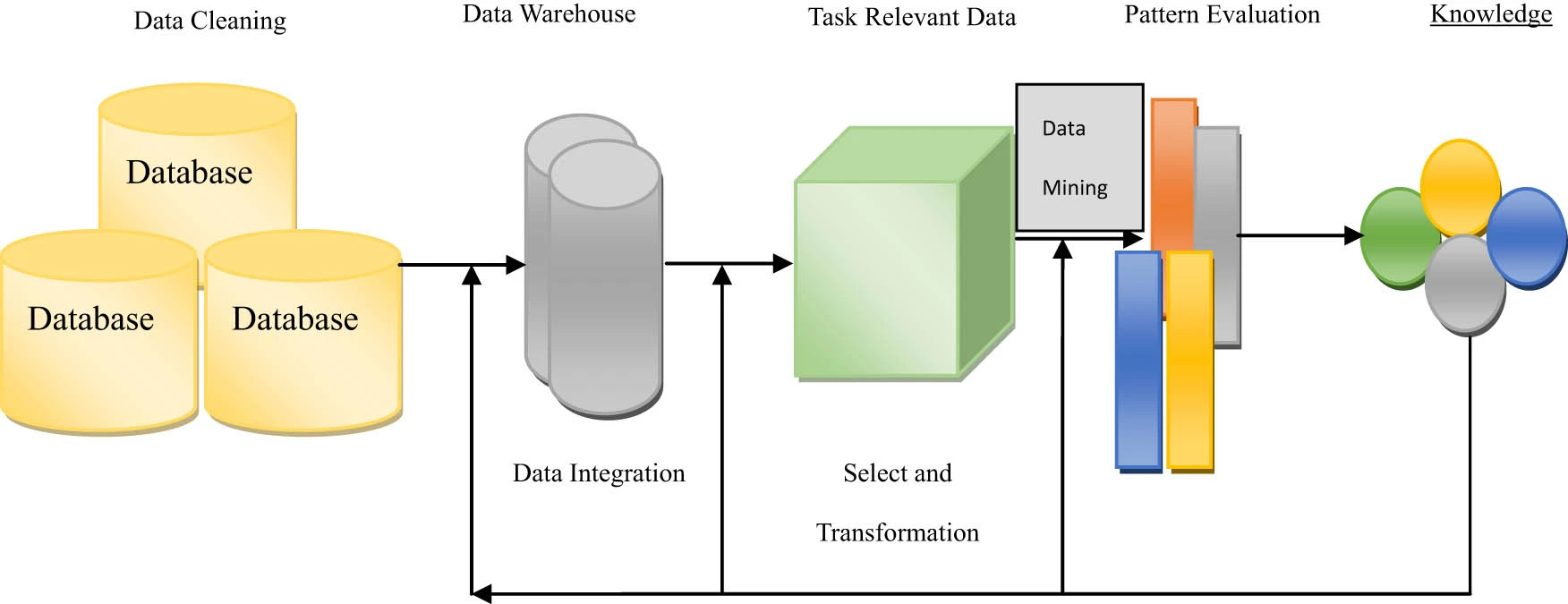
Data mining is an integral part of uncovering hidden insights and patterns from large datasets. One crucial technique used in data mining is association rule learning. But what exactly is an association rule and how does it work? This comprehensive guide will explain everything you need to know.
What is Association Rules in Data Mining?
An association rule is a data mining technique that uncovers relationships between variables in a dataset. It allows us to uncover correlations between items and events that occur together frequently.
For example, an association rule might discover that customers who purchase peanut butter at the grocery store often also buy jelly. Or it could identify that website users who visit page A frequently also visit page B in the same session.
Association rules are expressed like this:
Let’s break this down:
- The items before the arrow are called the antecedent – {Peanut Butter} in this case.
- The items after the arrow are called the consequent – {Jelly}.
- Support tells us how frequently the rule occurs in the dataset – 2% here.
- Confidence shows how often the consequent follows if the antecedent is true – so 60% of customers who purchased peanut butter also bought jelly.
By revealing these co-occurrence relationships, association rules allow businesses to cross-sell products, customize recommendations, plan store layouts, identify at-risk customers, and more.
Use Cases for Association Rules in Data Mining
Association rules have many applications across industries. Some examples include:
1.Market Basket Analysis
A classic use case is performing market basket analysis for grocery or retail stores. By analyzing purchase history data, retailers can identify products that customers frequently buy together. This allows stores to optimize the layout by placing associated products nearby to increase sales.
2.Product Recommendations
Ecommerce sites often use association rules to provide personalized product recommendations. By understanding what items a customer currently has in their cart or recently purchased, relevant associated products can be suggested to increase order values.
3.Financial Risk Modeling
In banking, association rules applied to customer transaction data may identify concerning patterns predictive of credit risk or fraud. Banks can then take proactive measures with these high-risk customers.
4.Medical Diagnosis
In healthcare, association rule mining on patient symptoms and conditions can improve diagnostic accuracy. By knowing related comorbidities, doctors can consider all likely diagnosis options.
5.Network Intrusion Detection
Cybersecurity experts apply association rules to Security and network traffic data to uncover suspicious or malicious user behavior patterns and strengthen systems against attacks.
And many more application across diverse industries…
Now that you have a sense of why association rules are useful, let’s look at how they actually work under the hood.
How Do Association Rules Work in Data Mining?
Generating association rules is a two-step process:
Step 1) Find all itemsets that meet the minimum support threshold
First, all the unique item combinations (also called itemsets) that appear frequently enough in the dataset need to be discovered. An itemset is considered “frequent” if it exceeds a user-defined minimum support threshold.
For example, if the support threshold is 2% in a grocery store dataset, then the itemset {peanut butter, jelly} needs to appear together in at least 2% of all transactions to qualify as frequent. Choosing the right support threshold is critical – too high and we miss insightful rules, too low and the number of combinations explodes.
Step 2) Generate rules from the frequent itemsets
Next, from those qualifying frequent item sets, we systematically generate rules to uncover the association relationships between the items. To do this, each itemset is divided into a consequent and antecedent, and the confidence metric is calculated. Confidence indicates how often the rule is actually true in the dataset. Typically, rules with >50% confidence are considered useful.
Behind the scenes, support and confidence help safeguard against false or meaningless rules being discovered just by random chance in large datasets. Carefully tuning these metrics is key for robust rule generation.

Algorithms for Generating Association Rules
Over the years, data scientists have developed efficient algorithms specifically for mining association rules from transactional data:
– Apriori Algorithm
The Apriori algorithm is one of the earliest and most influential algorithms for association rule learning. It uses a “bottom up” approach, starting with individual items (1-itemsets) and progressively expanding to larger itemsets until no more frequent itemsets are found.
Apriori relies on the principle that any subset of a frequent itemset must also be frequent. But This insight allows Apriori to efficiently reduce the exploration space of candidate itemsets. Once all frequent itemsets are known, rules can be generated.
Despite being over 25 years old, Apriori still sees widespread use today due to its intuitive logic and ease of implementation. Modern optimizations have also improved its feasibility for mining massive datasets.
– FP-Growth Algorithm
The FP-growth (Frequent Pattern growth) algorithm was proposed as an efficient alternative to Apriori. But It uses a compressed, tree-based data structure called an FP-tree to store transactions share common items.
Instead of the bottom-up approach in Apriori, FP-growth uses a divide-and-conquer methodology, decomposing mining into smaller conditional pattern mining tasks. Recursively growth of subtrees containing frequent pattern suffixes enables fast frequency counting.
FP-growth runs an order of magnitude faster than the Apriori algorithm and has better scalability for mining long patterns or massive databases. However, Apriori can perform better for small or sparse datasets.
In addition to these seminal algorithms, many Apriori and FP-tree variants have also been developed to further optimize performance, accuracy, or memory usage as needed for different applications.
Association Rules in the Context of Data Mining
Keep in mind association rule learning is just one technique in the entire toolbox of data mining methods:
1.Classification
Classification models like decision trees, random forests, neural networks also more are trained to predict categorical target variables from input data.
2.Clustering
Clustering algorithms like k-means organize data points into groups of similar characteristics without predefined outputs.
3.Regression
Regression fits mathematical models to continuously-valued also numeric variables for predictive forecasting and what-if analysis.
4.Forecasting
Time series forecasting uses historical time-stamped values to predict expected future values through modeling seasonality, trends and patterns.
5.Sequence Analysis
Sequence mining uncovers frequent subsequences, sequential patterns, motifs, or anomalous behaviors over time in complex sequence datasets like text, DNA, protein structures, music, trajectories, time series and more.
While each technique has different applications, they can often be used alongside association rules to uncover multidimensional insights. For example, first using clustering to segment customers, then applying association rule mining within each cluster.
Conclusion
In closing, association rule learning is a versatile data mining technique with vast applications for uncovering opportunity and risk by discovering interesting relationships between co-occurring items. It transforms transactional data into actionable insights for sales, recommendations, predictions and more across every industry.
Core concepts like support and confidence help pinpoint patterns that appear frequently and with strong certainty. Also seminal algorithms like Apriori and FP-growth efficiently sift through massive datasets to generate rules. With a solid grasp of these fundamentals, also applying association rules to uncover key insights hidden in your data is now within reach!
| If you are reading What is Association Rule in Data Mining? then also check our other blogs: | |
| Computer Virus | First Electronic Computer |
Now, understanding this concept is simple and entertaining on Hasons. By using Hasons website you can always stay one step ahead in your job, business or studies by purchasing New Age Desktops and All in One Desktops, i3 Intel Core Processor Desktop starting from 15000/-. Monitors, CPUs, Gaming Desktop are also available. Register on Hasons and order your Tech Partner Now. Get exciting offers and benefits on your every purchase. Contact us so our support team will guide you in purchasing your right Tech Partner.
Desktop Computer Set under 16k, Limited Edition!
I3 processor 8GB RAM 4th gen/500 GB HDD/ 128 SSD Wired Keyboard and Mouse/ Windows 10/Black, screen 18.5
Call 9766122859 to place an offline order and receive FLAT 500/- DISCOUNT
Association Rule in Data Mining
- What is an association rule in data mining?An association rule is a data mining technique for uncovering relationships between variables in a dataset that co-occur together frequently. It discovers patterns like customers who buy X product also tend to buy Y product. These rules are written as X -> Y with metrics like 2% support and 60% confidence.
- What is association and correlation in data mining?Association and correlation describe two related but distinct types of relationships patterns in data mining:
- Association refers to items or events that co-occur together as frequent itemsets, but not necessarily in a strict cause-and-effect relationship.
- Correlation indicates a stronger linear relationship between numeric variables, implying dependence and ability to predict.
- What is clustering and association rule in data mining?Clustering organizes data points by similarity without predefined groups. It might segment customers by common demographics and attributes. Association rule mining then uncovers interesting relationships between items only within certain clusters, allowing personalization. The two techniques can be combined for richer insights.
- What is Apriori in data mining?The Apriori algorithm is one of the most influential early algorithms for efficiently discovering frequent itemsets and generating association rules in massive transactional databases. It uses a bottom-up approach and principle that a subset of a frequent itemset must also be frequent.
- What are association rules in Apriori algorithm?The Apriori algorithm uncovers all itemsets that meet a minimum support threshold from transactional data. From these frequent itemsets, rules are created indicating associations between antecedent and consequent items A and B like: A -> B with metrics like 2% support and 60% confidence. These quantify the rules’ frequency and certainty in the dataset.